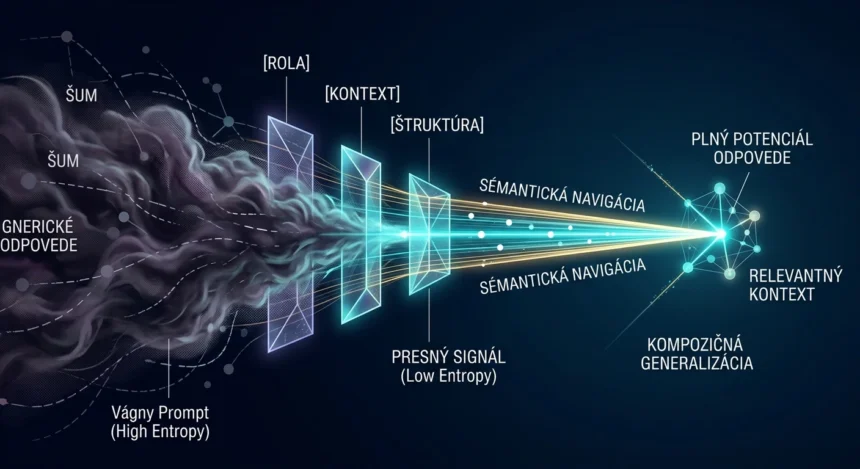
To, čo väčšina ľudí posiela generatívnym modelom, nie je otázka. Je to signál s vysokým šumom. Pozrime sa na fyziku toho, prečo vznikajú vágne odpovede a ako tento proces vedecky podloženým prístupom zmeniť.
AI vám nedáva zlé odpovede. Vy jej dávate zlý signál.
Väčšina ľudí nepoužíva AI zle preto, že by nevedeli písať. Používajú ju zle, pretože nevedia formulovať problém.
Otvoríte ChatGPT a napíšete: „Napíš niečo o marketingu.“ Dostanete päť odsekov. Všetko technicky správne. Nič skutočne použiteľné. Skúsite znova s „napíš lepší text“ — rovnaký problém, iné slová.
Problém nie je v AI. Ak dostávate generické odpovede, problém je v tom, ako rozmýšľate o zadávaní úloh.
1. Ako AI vlastne vytvára odpovede — a prečo na tom záleží
Väčšina ľudí si myslí, že AI funguje ako vyhľadávač — zadáte kľúčové slovo, dostanete výsledok. Realita je zásadne odlišná.
Každé slovo, ktoré napíšete sa preloží do číselných súradníc — vektorov v priestore s tisíckami dimenzií. Slovo „banka“ nie je len slovom. Je to bod v priestore, ktorý je zároveň blízko slov „peniaze“, „rieka“ aj „lavička“ — v rôznych dimenziách, s rôznymi váhami.
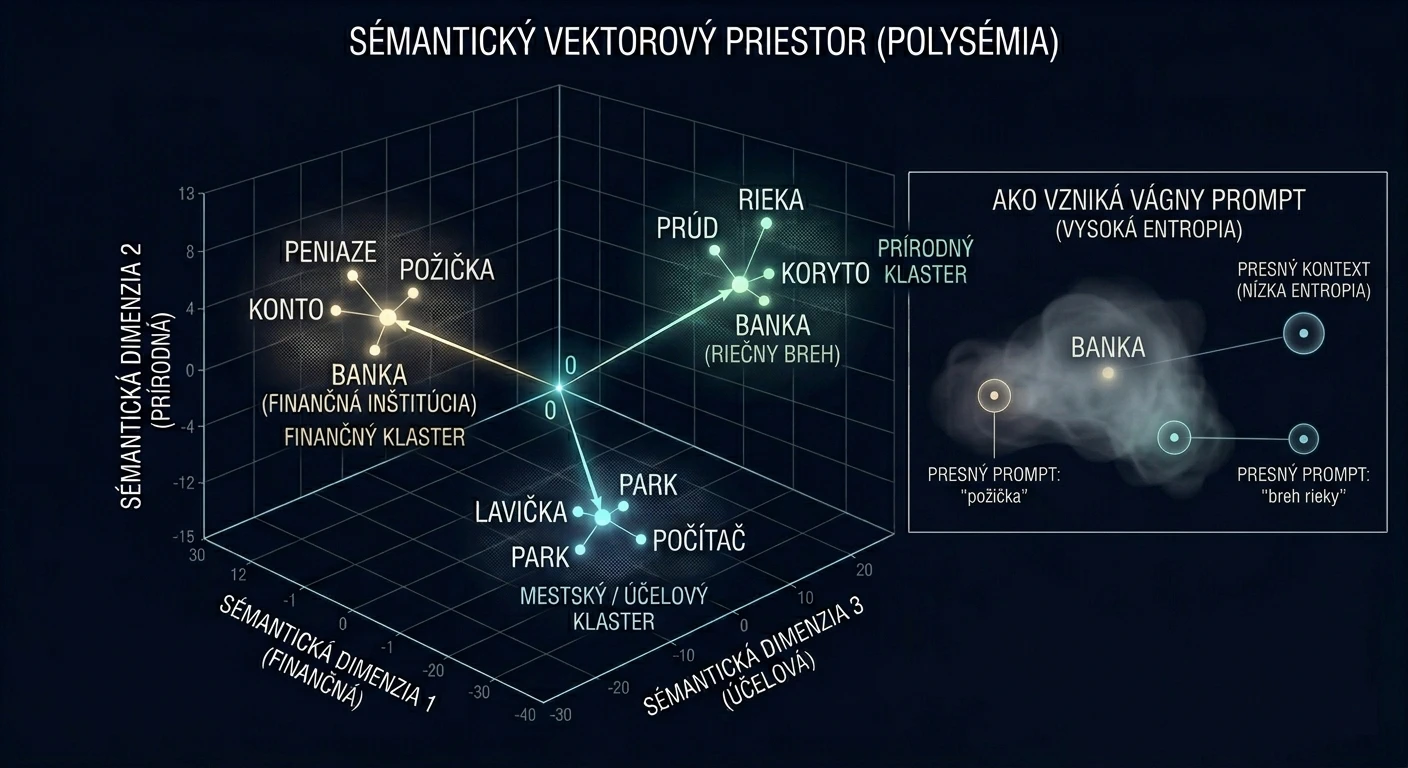
Keď zadáte prompt, model nehľadá správnu odpoveď. Naviguje v tomto priestore smerom k oblasti, ktorá je matematicky najpravdepodobnejšia — vzhľadom na všetky slová, ktoré ste použili. Nejde o vedomú navigáciu — ide o pravdepodobnostnú aproximáciu distribúcie ďalšieho tokenu, ktorý nie je vždy celé slovo, ale často len jeho časť (slabika/znak).
Dôležitý detail: táto navigácia nie je globálne plánovanie. Model generuje text token po tokene — každé slovo závisí od všetkých predchádzajúcich. Nevidí celú odpoveď vopred. Každý token je lokálne rozhodnutie. Preto je kontext na začiatku promptu tak zásadný — kotví každé nasledujúce rozhodnutie od prvého slova.
Vágny prompt = veľká oblasť možností = model si vyberie štatistický priemer. A štatistický priemer zaujímavého obsahu je nezaujímavý obsah.
💡 Praktické prirovnanie: Predstavte si sémantický priestor ako mapu. Keď zadáte neurčitý prompt „napíš o marketingu“, je to, akoby ste do navigácie zadali cieľ „niekam do Európy“. Model má k dispozícii celý kontinent a vyberie si náhodnú lokalitu. Ak však zadáte presné parametre, posúvate sa na konkrétne „súradnice“ v priestore významov – a výsledok je chirurgicky presný. Rozdiel nie je v dĺžke zadania, ale v hustote informácií, ktoré navigácii poskytnete.
2. Sémantická entropia: prečo AI niekedy klame
Farquhar et al. (2023, Nature) navrhli sémantickú entropiu ako metódu detekcie neistoty modelu: keď model na tú istú otázku vnútorne generuje odpovede sémanticky vzdialené od seba, signalizuje to vysokú neistotu — a vyššiu pravdepodobnosť halucinácií. Nejde o univerzálne vysvetlenie všetkých halucinácií. Je to merateľný proxy pre situácie kedy model nevie, kde v priestore sa nachádza spoľahlivá odpoveď.
Sémantická entropia teda nie je detektor klamstva. Je to detektor neistoty. A vágnosť promptu je jedným z faktorov, ktoré túto neistotu výrazne zvyšujú.
Toto je dôležité: halucinácie nie sú chyba modelu v zmysle „AI sa pomýlila“. Sú to výstup systému s príliš veľkou neistotou o tom, čo vlastne hľadáte.
Váš prompt je teda niečo viac než otázka. Je to navigačný signál. A kvalita navigácie závisí od presnosti signálu.
🔬 DEEP DIVE: Ako reasoning modely zmenili pravidlá hry
Situácia zo života: Použijete rovnaký prompt na GPT-3.5 a na o1 alebo Claude 3.7. Dostanete dramaticky odlišné výsledky — aj keď ste nič nezmenili.
Vedecké vysvetlenie: Staršie modely (pred rokom 2023) fungovali ako jeden krok: prompt → odpoveď. Moderné reasoning modely (o1, o3, Claude 3.7, Gemini 2 Flash Thinking) pred odpoveďou generujú interný reťazec uvažovania — chain-of-thought. Tento proces zvyšuje pravdepodobnosť konzistentnej odpovede — model má viac krokov na overenie vnútornej logiky predtým, než začne generovať výstup. Nie je to garancia správnosti. Je to šanca na koherentnejšiu navigáciu. Dôsledok pre vás: tieto modely sú menej závislé na presnosti vášho promptu — ale stále fungujú výrazne lepšie, ak im dáte správny kontext. Nie preto, že by boli „hlúpe“, ale preto, že kontext eliminuje priestor pre nejednoznačnosť skôr, než ho musí riešiť model sám.
3. Tri techniky ktoré skutočne fungujú
Toto nie je zoznam tipov. Je to sekvenčný protokol — každá technika útočí na iný zdroj neistoty.
Technika 1 — Sémantické kotvenie (kto ste, nie čo chcete)
Namiesto popisu výstupu popíšte kontext. Rozdiel:
❌ „Napíš marketingový text.“ ✅ „Si CMO B2B SaaS firmy so 50 zamestnancami. Váš produkt znižuje mieru odchodov návštevníkov. Cieľová skupina sú operations manažéri v scale-up firmách. Napíš email pre cold outreach (Akvizičné oslovovanie).“
Čo sa stalo technicky: prvá veta aktivovala rozsiahlu oblasť sémantického priestoru. Druhá ju sústredila do jedného špecifického klastra — kde žijú presne tie vzory, ktoré potrebujete.
Technika 2 — Štruktúra výstupu vopred
Moderné modely generujú text token po tokene — každý nasledujúci token závisí od všetkých predchádzajúcich. Ak definujete štruktúru odpovede na začiatku, model ju použije ako kotvu pre celé generovanie odpovede. Štruktúra funguje ako implicitný plán — model sa jej drží pri každom ďalšom kroku vytvárania odpovede.
❌ „Vysvetli mi rozdiel medzi SQL a NoSQL.“ ✅ „Vysvetli mi rozdiel medzi SQL a NoSQL. Použi tento formát: 1) jednoveté jadro rozdielu, 2) kedy použiť ktoré, 3) jeden konkrétny príklad z e-commerce.“
Technika 3 — Vektorová križovatka (kombinácia dvoch presných domén)
Toto je najpokročilejšia technika. Keď kombinujete dve špecifické oblasti, model hľadá priesečník v priestore kde klišé neexistujú — pretože väčšina trénovacích dát pokrýva tieto oblasti oddelene, nie ich kombináciu.
❌ „Ako budovať tím?“ ✅ „Aplikuj princípy z teórie systémov (feedback loops, emergent behavior) na budovanie predajného tímu v early-stage startupe.“
Výsledok nie je len „zaujímavejší“. Je štrukturálne odlišný — model nemôže siahať po bežných vzoroch, musí skutočne kombinovať. V literatúre sa tento jav označuje ako compositional generalization — schopnosť modelu kombinovať známe koncepty novým spôsobom, ktorý v trénovacích dátach neexistoval ako celok.
🔬 DEEP DIVE: Prečo „buď kreatívny“ nefunguje
Situácia zo života: Napíšete: „Buď kreatívny a napíš niečo originálne o mojom produkte.“ Dostanete päť odrážok s nadpismi ako „Revolučné riešenie pre váš biznis.“
Vedecké vysvetlenie: Inštrukcia „buď kreatívny“ je paradox. Kreativita v kontexte jazykových modelov znamená pohyb do menej frekventovaných oblastí sémantického priestoru — preč od štatistického priemeru. Ale aby model vedel, kam ísť, potrebuje súradnice: z čoho vychádza, čím je ohraničený, čo je zakázané. Bez týchto súradníc „kreativita“ produkuje štatisticky podpriemerné výsledky — model sa pohybuje náhodne v priestore, nie smerom k hodnotnému priesečníku. Konkrétny kontext je paradoxne podmienkou originality, nie jej opakom.
Praktický protokol: Prompt Canvas (Rámec pre štruktúrované zadanie)
Toto je štruktúra, ktorú môžete použiť pre akýkoľvek komplexný prompt. Každý element znižuje sémantickú entropiu v inej dimenzii.
[ROLA] Kto ste v tomto kontexte? (zvyšuje presnosť odborného klastra)
[KONTEXT] Aká je situácia? (kotví v priestore)
[ÚLOHA] Čo konkrétne má byť výstupom? (definuje smer)
[FORMÁT] Ako má vyzerať odpoveď? (kotví generáciu od prvého tokenu)
[OBMEDZENIA] Čo nechceš? (eliminuje nežiaduce oblasti priestoru)
Príklad:
„[ROLA] Si senior produktový manažér v B2B SaaS firme.
[KONTEXT] Pripravujem prezentáciu pre board o tom, prečo investovať do redesignu onboardingu. Mám dáta: churn (miery odchodov návštevníkov) v prvých 30 dňoch je 34 %.
[ÚLOHA] Pomôž mi sformulovať tri hlavné argumenty.
[FORMÁT] Každý argument: jedna veta tvrdenie + jeden dátový bod + jedna implikácia pre biznis.
[OBMEDZENIA] Nepoužívaj generické frázy ako ‚user experience je dôležitý‘.“
Toto nie je zdvorilostná vata. Je to navigačný systém. Presný prompt nezaručuje správnu odpoveď. Zaručuje len to, že model rieši správny problém.
Príklad — seminárna práca o keynesiánskej ekonómii (AI ako akademický nástroj)
Fáza 1 — Pochopenie a orientácia v téme (AI ako vysvetľovač)
„[ROLA] Si vysokoškolský pedagóg ekonómie, ktorý vie vysvetľovať zložité koncepty jednoducho a presne.
[KONTEXT] Som študent druhého ročníka a učím sa základy keynesiánskej ekonómie.
[ÚLOHA] Vysvetli mi tri najčastejšie omyly alebo nepochopenia keynesiánskej teórie.
[FORMÁT] Pre každý bod:
– čo si študenti často myslia
– ako to je v skutočnosti
– prečo je tento rozdiel dôležitý v praxi
[OBMEDZENIA] Vyhni sa čisto učebnicovým definíciám, vysvetľuj cez pochopenie, nie memorovanie.“
👉 Cieľ: rýchle pochopenie problematiky a vytvorenie mentálneho modelu témy.
Fáza 2 — Formovanie vlastnej myšlienky (študent ako autor)
Na základe pochopenia si študent vytvorí vlastnú výskumnú otázku alebo tézu.
Príklad:
„Keynesiánske stimulačné politiky majú odlišné účinky v malých otvorených ekonomikách než vo veľkých uzavretých ekonomikách.“
👉 Dôležité pravidlo:
Téza, argumenty aj záver sú výlučne vlastná analytická práca študenta. AI ich nevytvára, iba pomáha lepšie pochopiť kontext.
Fáza 3 — Kritické myslenie (AI ako oponent)
„[ROLA] Si akademický recenzent (peer reviewer) v oblasti ekonómie.
[KONTEXT] Pripravujem seminárnu prácu s touto tézou: [vlastná téza študenta].
[ÚLOHA] Identifikuj tri možné slabiny alebo protiargumenty.
[FORMÁT] Pre každý bod:
– slabina alebo riziko v argumentácii
– otázka, ktorú by položil kritický oponent
[OBMEDZENIA] Neponúkaj riešenia — iba kritickú analýzu.“
👉 Cieľ: zlepšenie kvality argumentácie a schopnosti obhájiť vlastné závery.
Fáza 4 — Jazyková a štrukturálna kontrola (AI ako konzultant)
„[ROLA] Si akademický jazykový konzultant.
[KONTEXT] Mám napísanú časť seminárnej práce a chcem zlepšiť jej zrozumiteľnosť a logickú štruktúru.
[ÚLOHA] Pomôž mi identifikovať miesta, ktoré sú nejasné alebo slabšie formulované, a navrhni ich lepšie vyjadrenie.
[FORMÁT]
– návrh zlepšenej štruktúry
– návrh preformulovaných viet (bez zmeny významu)
[OBMEDZENIA] Nemeň obsah ani argumenty, iba jazyk, prepojenia a čitateľnosť.“
👉 Cieľ: zlepšenie kvality textu bez zásahu do autorstva myšlienok.
Akademický princíp používania AI (praktické pravidlá)
Aby bol postup kompatibilný so štandardmi akademickej integrity:
-> AI slúži na pochopenie, testovanie myšlienok a zlepšenie formulácie
-> všetky argumenty a závery musia byť výsledkom vlastného myslenia študenta
-> študent musí vedieť vysvetliť a obhájiť každý použitý argument
-> AI sa nepoužíva ako autor textu, ale ako nástroj na zlepšenie kvality práce
-> fakty a dáta musia byť overené z odborných zdrojov
Návrh experimentu
Téma: Vysvetlenie umelej inteligencie pre niekoho kto o nej nič nevie.
Rovnaká úloha, tri rôzne signály. Každý prompt bol zadaný rovnakému modelu (Claude Sonnet / GPT-4) bez predchádzajúceho kontextu.
PROMPT A — nulový kontext
„Vysvetli mi umelú inteligenciu.“
Výsledok: Štyri odseky. Definícia z učebnice. Zmienka o strojovom učení, neurónových sieťach a ChatGPT. Záver o tom, že AI mení svet. Nič čo by ste nenašli na Wikipédii — a nič čo by ste si pamätali zajtra.
Sémantická neistota: vysoká. Model nevie či hovorí s dieťaťom, študentom, novinárom alebo inžinierom. Vyberie štatistický priemer — text, ktorý nevyhovuje nikomu konkrétne.
PROMPT B — čiastočný kontext
„Vysvetli mi umelú inteligenciu jednoducho. Som začiatočník.“
Výsledok: Kratší text. Menej žargónu. Prirovnanie k „mozgu v počítači.“ Stále generické — ale čitateľnejšie. Model dostal jeden parameter (začiatočník) a zúžil priestor. Ale stále nevie: aký vek, aký cieľ, čo robíte s touto informáciou.
Sémantická neistota: stredná. Lepšie než A, ale stále široká oblasť možností.
PROMPT C — Prompt Canvas
„[ROLA] Si učiteľ, ktorý vysvetľuje komplexné témy cez každodenné príklady.
[KONTEXT] Hovorím s päťdesiatročnou účtovníčkou, ktorá počula o AI v správach a chce pochopiť čo to vlastne je — bez technického žargónu.
[ÚLOHA] Vysvetli čo je AI a ako funguje.
[FORMÁT] Jedno hlavné prirovnanie z každodenného života + dve konkrétne situácie kde sa s AI už stretla bez toho aby o tom vedela.
[OBMEDZENIA] Žiadne slová ako algoritmus, neurónová sieť, model alebo dataset.“
Výsledok: AI je prirovnaná k skúsenej sekretárke ktorá prečítala milión emailov a vie odhadnúť čo jej šéf potrebuje — bez toho aby jej to povedal explicitne. Dve situácie: odporúčania na Netflixe a automatické triedenie spamu. Žiadny žargón. Okamžite použiteľné vysvetlenie.
Sémantická neistota: nízka. Model dostal presné súradnice — a prestal hádať.
Analýza — čo experiment ukazuje:
Rozdiel medzi A a C nie je v tom, že model „pracoval tvrdšie.“ Čas generovania bol takmer identický. Rozdiel je výlučne v presnosti signálu.
Prompt A dal modelu celý sémantický priestor — od detskej encyklopédie po doktorandskú prácu. Prompt C ho zúžil na jeden bod: päťdesiatročná účtovníčka, každodenné prirovnanie, nulový žargón.
Toto je merateľný rozdiel: ak by ste dali výstupy A a C stovke ľudí s profilom cieľovej osoby a pýtali sa, „ktoré vysvetlenie vám dáva väčší zmysel“ — výsledok by nebol blízky. Bol by jednoznačný.
Rovnaká otázka, tri rôzne signály:
Prompt A — „Napíš email zákazníkovi.“ Výsledok: formálny päťodsekový email s nadpisom „Vážený zákazník“ a záverom „S úctou.“
Prompt B — „Napíš krátky follow-up email zákazníkovi, ktorý sa nezaregistroval po demo calle.“ Výsledok: lepší, ale stále generický. Model nevie čo bolo na demo calle, prečo nezaregistroval, čo ponúkate.
Prompt C — „[ROLA] Si account executive B2B SaaS firmy. [KONTEXT] Zákazník videl demo nášho HR nástroja, ale nezaregistroval sa. Z CRM vieš, že má tím 80 ľudí a problém s onboardingom nových zamestnancov. [ÚLOHA] Napíš follow-up email. [FORMÁT] Max 5 viet. Jeden konkrétny odkaz na jeho problém. Jasná výzva k akcii. [OBMEDZENIA] Žiadne „dúfam že sa máte dobre“.“ Výsledok: personalizovaný, konkrétny, priamo adresuje problém zákazníka.
Rozdiel nie je v tom, že AI „pracovala tvrdšie“. Je v tom, že sémantický priestor bol zúžený z celého vesmíru emailov na jeden presný bod.
Najlepšie prompty nie sú tie najdlhšie. Sú tie, ktoré minimalizujú neistotu.
Kedy ani presný prompt nepomôže
Tri situácie kde technika zlyháva bez ohľadu na kvalitu promptu:
Model nemá relevantné trénovacie dáta — ak pýtate fakty o udalostiach po dátume tréningu alebo o interných dátach vašej firmy, presnosť promptu problém nerieši. Tu treba RAG (retrieval-augmented generation) alebo externé zdroje.
Prompt je príliš rigidný — ak definujete každý detail výstupu, model nemá priestor na kompozíciu. Najlepšie výsledky vznikajú z kombinácie pevného kontextu a otvoreného priestoru pre generáciu.
Žiadate deterministickú správnosť od pravdepodobnostného systému — AI nie je databáza ani retrieval systém — je to generatívny model, ktorý aproximuje pravdepodobné pokračovanie textu. Aj pri perfektnom prompte môže generovať uveritelné, ale nepresné čísla, dátumy alebo citácie. Kritické fakty vždy overte.
Záver: vy ste pilot, nie pasažier
AI v roku 2026 nie je digitálna encyklopédia. Je to systém na navigáciu v sémantickom priestore — a kvalita navigácie závisí od presnosti vašich súradníc.
Rozdiel medzi používateľom, ktorý dostáva generické odpovede a používateľom, ktorý dostáva presné, použiteľné výstupy nie je v tom, komu AI „lepšie funguje“. Je to rozdiel v tom, kto rozumie čo vlastne zadáva.
Vágny prompt nepýta AI o pomoc. Žiada ju aby uhádla čo chcete. A uhádnutie je vždy horší výsledok ako navigácia.
Každý prompt je signál. Čím je presnejší, tým menej priestoru zostáva na šum — a tým viac sa AI prestáva hádať a začína spolupracovať.
Zoznam literatúry
- Farquhar, S. et al. (2024). Detecting hallucinations in large language models using semantic entropy. Nature, 630, 625–630.
- Wei, J. et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems (NeurIPS), 35, 24824-24837.
- Mikolov, T. et al. (2013). Distributed representations of words and phrases and their compositionality. Advances in Neural Information Processing Systems (NeurIPS), 26.
- OpenAI (2023). GPT-4 Technical Report. arXiv preprint arXiv:2303.08774.




